This short post is a call to arms for Tsetlin Machines (TMs), a somewhat academic outsider’s view of what the community has and what is missing. The discourse is biased to commercial usages of the technology, a vital step forward in establishing the true value of the algorithms discussed in this blog post..
Introduction 🔗
Tsetlin Machines are a new class of classifier that have significant usability and performance benefits over both standard classifiers, and most interestingly over existing deep learning (DL) systems. Clearly to establish the usefulness of the algorithm the technology needs to step outside of the academic community and become accepted in a wider context, which inevitably means touching commercial systems. In this paper we attempt to describe steps that will help make this possible.
Benefits 🔗
The commercial benefits are as follows:
- As simple classifiers they perform in line with the best “out-the-box” ensemble classifiers such as XGboost, so there is no downside in using them in the traditional small data classification setting.
- For big data problems, (like image and text analysis) They are highly extensible and can exist (in a similar way to the perceptron in both a deep and convolutional format. This is a vital advantage working with image data and these methods offer best in class performance on this type of data-set.
- Their internal structure is fundamentally boolean so they have the capacity to be explained. This works well in the small data setup and also for text based classification.
- The training regime usually converges very easily with typically 10s of epochs rather than the 1000’s of a traditional MLP, so is low energy.
- The training produces a specialised boolean network which is highly efficient for inference, and therefore extremely useful in an edge setting. Traditional DL models are known to be difficult to train in a boolean setting, and the process of converting from high to low quantisation is still fairly ad-hoc.
- To follow this up, work has already been performed to design and build specialist hardware and this project will utilise this where necessary to prove out the on the edge efficiencies.
- They can easily be connected to non boolean deep learning front-end systems to hybridise. The use case for this being the pre-processing being done at high quantisation levels and the dense decisions being done in the boolean setting of the tsetlin machine.
- Because of the boolean nature of the software it can be easily tested using fuzzing based approaches, this gives an extra layer of safety critical support.
A Workflow for Considered Edge Deployment 🔗
Below is a workflow for deployment of a TM.
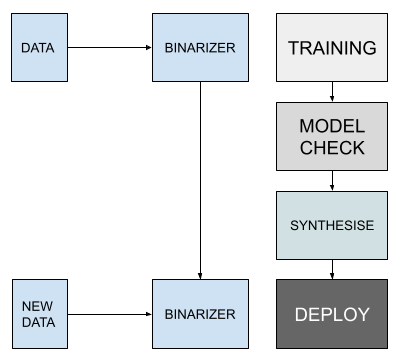
There are several benefits of this over, say, a Binarized Neural Network (BNN), the most obvious being an intermediate model check because of the boolean nature of clauses. Secondly, the explicit binarization of the training and inference data is also a feature as it means that this can be tuned to the data present at training.
A Call to Arms… 🔗
Critical Messaging that Hasn’t Been Provided 🔗
One of the big problems is that the technology is swimming against the tide of deep learning models, which clearly have revolutionised several areas of pattern recognition. What would be best to do as a community is work on becoming a complimentary technology, competition is to some extent pointless and will only serve to marginalise the technology, the community needs to look more closely at hybridised approaches.
Critical Infrastructure Missing 🔗
- Pytorch/Keras Layer Without a layer for the major DNN pipelines TMs stands little chance of being integrated into existing project. Undoubtedly a well implemented layer is the one single step that will increase adoption, and Pytorch seems to be the industry standard.
- Auto-binarizer An efficient binarizer which can be deployed on the edge with minimum effort is vital to moving the pipeline from a server based setup to the edge, as it goes part and parcel with the model setup. Again, I think this is a real feature and can add to the validation aspect of this work.
- Model Check Explaining the binary clauses in a consistent and transparent way is a really potent potential feature of TMs. DL is very black-box and many industries are crying out for more transparent classification, indeed several (defence, healthcare, legal and safety critical) cannot move into automation without this. Some work has been done on this but high level tooling is not yet in place.
- Edge Deployment Work has been done on this, but the commercial technology offering requires a full end-to-end delivery platform. This area is tremendously exciting and again edge Internet of Things (IOT) solutions are crying out for TM style technology.
Conclusions 🔗
We see a great future for TMs and hope that this paper, despite being less academic, can stimulate a more wide ranging discussion on the technology.